Weastie.com goes serverless and frameworkless! Discussion of architecture and pros/cons
cloudaws1595409309840
As of yesterday, Weastie.com is officially serverless and frameworkless! So what exactly does this mean?
Previously, Weastie.com was hosted on a server in the AWS cloud on an EC2 virtual machine, using node.js and express for the backend. There is nothing inherently wrong with that -- it had perfect uptime and scored >=98% on Google Pagespeed Insights. There's a lot of cool things you can do with an actual server, for example I had the ability to spin up a proxy, a game server, a chat server... etc.
Now, the architecture behind Weastie.com is much different. Basically, whenever a request is made to Weastie.com, a node.js script is run on the cloud which can take in some information such as what page you are requesting, what your cookies are, etc. and returns back a web page. So yup, basically every time you make a request to weastie.com, it's almost as if a miniature web server is booted up to process your single request, then it shuts down as soon as it finishes. But the important thing to note is that there is no consistent "server" that runs this website. Technically, there is no such thing as true serverless because there has to be some form of server, but in this case I am essentially borrowing one of Amazon's servers for a couple milliseconds each time.
That sounds slow... doesn't it? Every single request we have to boot up a new mini web server, really? Well, if you check for yourself, as long as you are in the US I bet that this page will load in less than 0.5 seconds, for me personally I get roughly 0.1-0.3 second load time. I achieved this speed through a series of optimizations I made, but most of it boils down to the fact that I custom made my own "framework", optimized for serverless, which I will discuss in further detail below.
Cloud architecture
The cloud architecture behind weastie.com is based around 3 endpoints: weastie.com (the main website), assets.weastie.com (static file storage), and www.weastie.com (redirects back to weastie.com).
weastie.com
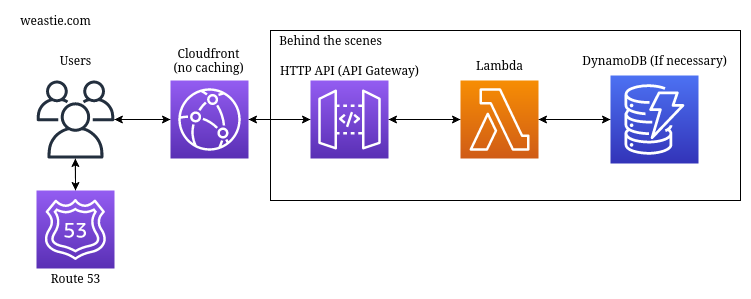
Any serverless gurus will find this architecture to be quite interesting. In general, a serverless website architecture generally boils down to using an s3 bucket to serve static HTML files, which accesses an API in order to perform any server-side tasks, such as querying databases. However, making use of the HTTP API Gateway, I decided to essentially cut out the middle man. When people think of APIs, they generally think of something that returns a JSON, an XML, etc. But, we have the ability to overwrite the "Content-Type" header returned by the API Gateway, so if we manually change that to "text/html", then there is no reason to not directly access an API at the root level. I originally got this idea by looking at Zappa, which uses a very similar idea but they use a REST API instead of an HTTP API, which loses some speed and is more expensive, as per this Amazon link.
For most cases, I would argue that the traditional architecture of using an S3 bucket to serve HTML files, then accessing an API for any server-side task is better. The HTML files can be cached so they can return very quickly. However, for my use case, using a static S3 web server would not work. I have a situation (mostly just the HTTP request listener) where I need to perform server-side tasks the moment a request is made, therefore serving static HTML files is not an option. Additionally, by serving files directly from the API Gateway, I get the added benefit of server-side rendering. That's why when you load this page, the blog is immediately built into the HTML, instead of giving you a "loading" page while a request is made to the API to retrieve the blog.
As per CloudFront, the main reason I use it is because I want http://weastie.com to redirect to https://weastie.com, which can not be done with just an HTTP API because APIs are designed only to work with HTTPS. It's a bit odd but I actually had to disable caching on CloudFront. Because HTML pages are dynamic rather than static, any form of caching would screw that up. I also get the added benefit of being able to add firewalls and have more control over the domain.
assets.weastie.com
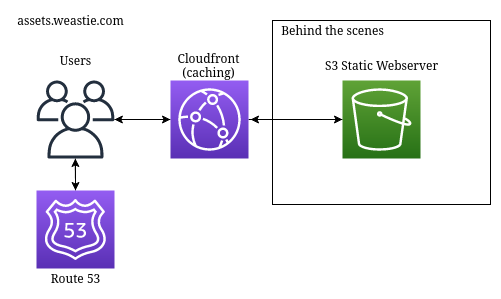
You see that image right above this? That is served from assets.weastie.com. The main issue with my architecture for weastie.com is that it is designed to serve dynamic files. If I tried to use the same server to also serve my css code, javascript code, and images, then it would be very inefficient and slow. The architecture is very simple, it just uses an S3 static web server connected to a caching CloudFront.
www.weastie.com
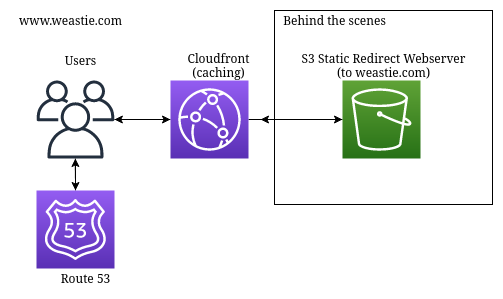
The only reason I have any architecture at all for www.weastie.com, is because I wanted to make sure that if anyone manually typed in my url as www.weastie.com, it would redirect to the actual website, weastie.com. For this, I use an empty S3 bucket web server set up to redirect all requests, and I had to put it behind CloudFront so that https://www.weastie.com would also redirect to weastie.com.
Lambda code and optimizations
Reminder: weastie.com is open source, and all the code can be found here: https://gitlab.com/weastie/weastiecom-serverless.For how fast Weastie.com is, you would think that I allocated the main Lambda a ton of memory and CPU usage. As of now, I only actually increased the memory usage from 128mb to 256mb, just to shave off a few milliseconds. But really, this Lambda is not that powerful, so how is it so fast?
As I discussed in the intro, I do not use any web frameworks. Tools such as serverless.com and Zappa both revolve around this idea of "simulating" a web framework in a serverless manner, which admittedly makes it significantly easier to migrate from server to serverless. However, this whole process of loading the massive amount of code and dependencies behind frameworks (which are intended to only be run during startup, but now every request includes a startup) takes too much time.
One of the main purposes of a web framework is to make handling web requests easier. It does all the stuff such as parsing the HTTP request, setting the right headers, etc. But... we don't need that do we? API Gateway does all that stuff for us. So essentially, if you are using a web framework with API Gateway, then the only real benefits you get are some of the built-in functions they have, which in my case were really easy to replicate and remake myself.
I based my custom "framework" off of express, since I liked the syntax they used. Here's what I actually had to write my own code for:
- Routing (the only hard part here was to get url variables, such as if the user makes a request to /blog/{some_id}/{some_title}, but even that only took like 20 minutes to get working. Query parameters and posted data are handled by API Gateway)
- Setting cookies (it's just adding a header)
- Redirects (adding a header and correct status code)
- Handling sessions (I cheated a little bit by using the npm package jsonwebtoken, I also only use sessions to handle requests made to /admin)
- Rendering pages with pug (more below)
As you can hopefully see, there really isn't that much there. Those functions really weren't that hard to write myself.
Server-side rendering
Server-side rendering is the reason why when you load this page, the blog is directly built into it. Basically, on the "server" side, it can take in some variables and place them directly into the HTML code before sending it off to the client.
Server-side rendering was also my first main optimization issue. To handle server-side rendering, I use pug. Pug is absolutely amazing, you get to write HTML code in a much easier syntax, and it has built in XSS protections by default (because the default option when inserting variable code is to escape it, and you have to manually tell it not to escape the code if you want it to be rendered).
On my laptop, if I tell pug to render a pretty basic .pug file, it takes roughly 10-20ms. My assumption that this would work the same way on Lambda was a mistake. As I mentioned before, this Lambda is allocated very little resources, so the same .pug files that would take 10-20ms for my laptop to render, took the lambda 300-800ms to render. Yikes. My first idea to solve this was to allocate my Lambda a bunch of resources, which did work but it would have made the Lambda so much more expensive. Luckily for me, pug has a builtin functionality to pre-compile pages into a javascript file. So, in my script to deploy out my Lambda, I added a node.js script that takes in a JSON of my .pug files, and pre-compiles them before the code is uploaded to the Lambda. That way, when the Lambda is run, it can execute those compiled render scripts which only takes a couple milliseconds. Thus, my dreams of going serverless have been saved.
Benefits of going serverless
It's cheap
Going serverless is *so* cheap, I'll come back and edit this a month from now but my current guess is that it would cost me $0.70 to run this website a month.
Now it's important to keep in mind that weastie.com was never expensive to run. I get minimal traffic, mostly just from friends or people who want to use my hack/music tools. Before I went serverless, I paid about $14 a month, almost all of it coming from running an EC2 machine 24/7. But now, I only have to pay when someone actually accesses my website, and how much does that cost?
Well, I can't calculate it exactly, but here's a summary of the services I use and their pricing (taken from Amazon websites).
- Lambda: At 256mb, it costs approximately $0.0000004166 per execution. That means a million requests would cost $0.42.
- Cloudfront: $0.01 for 10,000 HTTPS requests. That means a million requests would cost $1.00.
- API Gateway: $1.00 for 1 million requests.
- DynamoDB: $1.25 for a million write requests, $0.25 for a million read requests.
- S3 Static Server: $0.0004 for 1000 HTTP requests. That means a million HTTP requests would cost $0.40.
- S3 storage: Doesn't matter, I don't store that many images/files. The cost for me will always be $0.00
- Route 53: Static $0.50 a month for one hosted zone
So, even if my website actually got a lot of traffic and I got around a million page visits a month, it still would only cost around $4 a month.
Infinite scalability
Yup, you heard that. Infinite scalability. You may have heard people use the term "auto-scaling", to refer to some form of service or virtual machine automatically making itself more powerful when needed, and less powerful when not. For example, when a website gets a lot of traffic, perhaps the web server running it is allocated more memory/cpu power in order to keep up.
But here's the kicker: I don't need auto-scaling. I don't actually have any services that need to be scaled up or down. Every AWS tool I use scales "infinitely", exactly when it needs to. How does that work?
Well, think about the idea that my website is run on a Lambda. To put in super basic terms (and also because I don't really know how it actually works), when a Lambda is run, Amazon basically just needs to pick any of their servers in the region that is currently available, and tell it to execute the code. I don't manage any of the infrastructure. That means, as long as Amazon has a computer that is available, my website is available. I could go from 1 request a year to 1 thousand requests a second, and you wouldn't even notice for a split second. Auto-scaling takes some time to upgrade the power behind your services but infinite scaling is instant.
No handling of infrastructure
I don't ever have to worry about installing system updates on my web server, or writing a bunch of scripts to automatically perform silly system management tasks. All of that is managed by Amazon.
Downsides of going serverless
As much as I want to brag about how cool going serverless is, I have to be honest and admit that there are a few downsides to it too.
Infinite scalability can be... bad?
Right now, I don't run any ads on my website, nor do I have any paid services. I pay for everything out of pocket. So, let's say something were to happen and all of a sudden my website gets famous. I get millions of people coming in every day. So cool! But, now my costs are skyrocketing. I could all of a sudden be paying upwards of $10 a day (wow, that's still incredibly cheap). But the issue is, I wouldn't want that. I don't want to have to pay $300 a month to run my website if it makes me no money back. Basically, had my website been run on a non-scaling web server, I would still only be paying $20 a month and it would just be slower, which in some cases would be better than paying $300 a month for a faster site. It all depends.
And of course I should mention that in AWS, you can configure your infinite scaling. You can throttle your services so they aren't used too much, but doing that in a way can take away from the beauty of infinite scaling. Right now I'm kind of just hoping this doesn't happen. I'll look into more throttling later, but right now I don't have it configured.
I'm limited in some ways
Having Amazon handle all of the infrastructure behind my website is really nice, but in some odd case where I want to do something wacky or fun with the infrastructure, I no longer have that option. I don't know if I'll ever want to do something like that, but it's important to keep in mind.
Conclusion
In conclusion, Weastie.com is now entirely run by a series of AWS Cloud operations. The website is significantly cheaper to run (~$0.70 a month vs. $14 a month) at the same speed (faster in some cases). I performed a variety of optimizations to make it so fast, including building my own custom framework. My website will scale infinitely and likely have 0% downtime.